The ability to generalise is one of the primary desiderata of natural language processing (NLP).
Yet, how "good generalisation" should be defined and evaluated is not well understood,
nor are there common standards to evaluate generalisation.
As a consequence, newly proposed models are usually not systematically tested for their ability to generalise.
GenBench's mission is to make state-of-the-art generalisation testing the new status-quo in NLP.
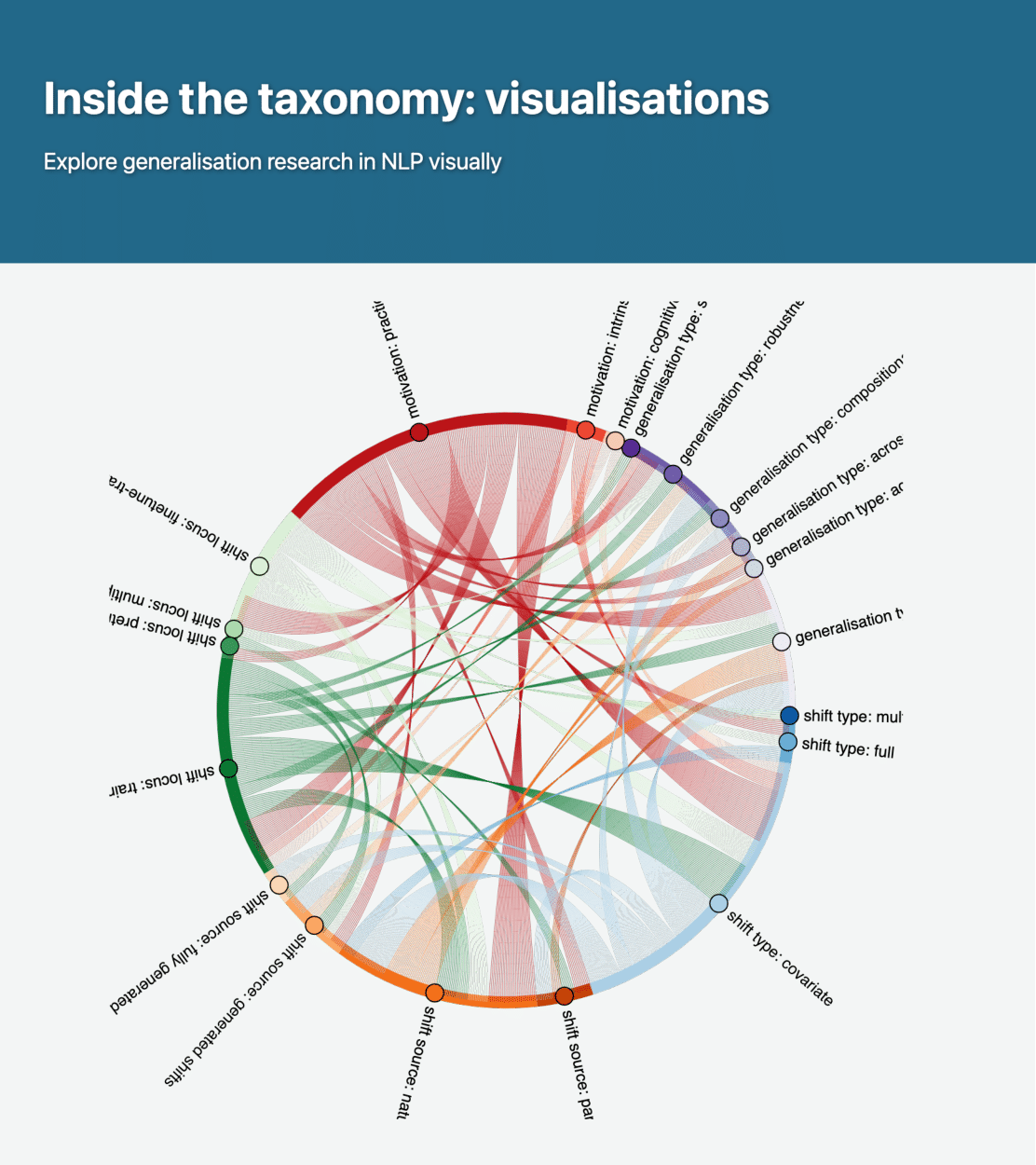
As a first step, we present a generalisation taxonomy, describing the underlying building blocks
of generalisation in NLP. We use the taxonomy to do an elaborate review of over 400 generalisation papers,
and we make recommendations for promising areas for the future.
You can find all this information in our taxonomy paper.
On this website, you can learn about the taxonomy,
you can visually explore our results,
create GenBench Evaluation Cards for your research papers,
and get citations from our analysis or contribute papers
that we will periodically add to our review.




News
| July 30, 2024 | The video summary of our Nature Machine Intelligence paper is live. Watch it here! |
| May 1, 2024 | The new GenBench workshop page is live, visit for more information. See you at EMNLP In Miami in November! |
| October 23, 2023 | Delighted to announce the GenBench 2024 Workshop will come back @ EMNLP 2024. |
| October 20, 2023 | A taxonomy and review of generalization research in NLP paper published @ Nature Machine Intelligence. |
| June 8, 2023 | GenBench Workshop Papers submission link is now available. |
| March 27, 2023 | The First GenBench workshop will be held @ EMNLP 2023 in Singapore from December 6 to 10, 2023! |